Meshing around

一开始去了解 TailScale 的时候是为了换掉 FRP. 为了方便调试, 以前在 K8s 集群放了个 frpc 的 pod. 但是这些 pod 在上次等保测评的时候差点儿出问题. 毕竟 frp 这东西原理上确实像个 malware. 也经常被当作 malware 来用. 所以对于云厂商来说, 跑在容器里的 frpc 简直就是打了个聚光灯在自己身上高喊着这是个风险. 我还特意试了一下, 直接在 host 上运行 frpc 反倒是不会被认为是风险, 但是试图在容器里运行的话, 进程会立刻被终止掉. 甚至是在没开主机安全防护的情况下. 虽然只试了腾讯云, 但是估计其他家也是差不多的策略.
既然是个争议工具, 那就干脆换掉就好了. 市面上有一大堆 frp 的变体. 做的也都是一样的事情. 但是就特征来说, 它们也都跟 frp 一样. 既然如此, 也就一样有被认定为恶意软件的可能性, 只是时间问题.
对于 TailScale 这类 Mesh Network, 所有节点的点对点直接连接听起来还是很诱人的. 但是在我的使用场景里, 真的点对点直接连接似乎会成为问题. 毕竟一个 Managed K8s Cluster, 上面不知道叠了多少层 NAT. 即便 TailScale 在这方面做了很多工作, 也很难保证这个集群的某层网络有入站白名单.
想过直接用 TailScale 的官方 Coordination Server, 不过鉴于大陆糟糕的网络环境, 说不定哪天就连不上了. 还是得自己搞. 好在有个开源项目 HeadScale, 实现了大部分 TailScale Coordination Server 的功能, 那就好办了.
大致读了一下 HeadScale 的文档, 还是挺简单的, 无非强调了一些为了跟 TailScale 兼容, 必须用 https 一类的事情. 这年头 https 不都标配了么, 小事. 当然, 虽然是小事, 但也总想偷个懒. 是不是可以请赛博活佛来处理 tls 握手, 这样就不用我自己配 nginx 了. 想的是挺美. 一试就会发现, 如果用 CloudFlare 的 tunnel 来路由 HeadScale , 会出现客户端在登陆的时候, 也就是 tailscale up --login-server https://headscale.xxx.com 的时候, 会卡死(实际在实验之前有问过 Claude 和 GPT 4o. Claude 是有联网搜索能力前的3.7 Sonnet. 两个模型都告诉我说这是极好的方案. 请勿迷信语言模型. 这东西的局限性会让你在错误的路上越走越远). 百思不得其解. 明明我之前用 tunnel 来路由我 bark 的流量还挺好用的. 继续翻文档. 果然 issue 里提到了 tunnel 后的 HeadScale 连接问题. TailScale 用了个非标准的 WebSocket 协议. 既然不能指望活佛去支持这种客制化协议, 那就只能自己搞了.
闲置域名反正是有的, 配个 certbot 去拿 SSL 证书就好了. 因为域名的 DNS 也在 CloudFlare, 那就直接创建个 token 给 certbot 去用就好了.
sudo apt install certbot python3-certbot-dns-cloudflare
echo "dns_cloudflare_api_token = xxx" > ~/.secrets/certbot/cloudflare.ini
chmod 600 ~/.secrets/certbot/cloudflare.ini
#因为后面需要配 HeadScale, HeadPlaine(UI), 而且打算分开不同的域名来访问, 干脆获取个通配符的证书比较好.
sudo certbot certonly --dns-cloudflare --dns-cloudflare-credentials ~/.secrets/certbot/cloudflare.ini -d xxx.com -d *.xxx.com
#certbot 默认的 propagation wait 是10秒, 不太够, 增加到 60 秒.
sudo ehco "dns_cloudflare_propagation_seconds = 60" >> /etc/letsencrypt/renewal/xxx.com.conf
#检查一下 certbot 的任务计划.
sudo systemctl status certbot.timer
#测试一下证书的更新.
sudo certbot renew --dry-run
HeadScale 本身只包含一个服务端. 所有的管理都需要通过命令行, 虽然问题不大, 但每次都要登录到部署的机子上也是挺麻烦的, 干脆同步部署一套 UI. HeadScale 在文档里提及了好几个 UI 实现, 最后还是选择 HeadPlane. 和官方管理后台最像的一个, 降低一些学习成本. 虽然我一直印象中 HeadScale 在什么地方提到说最好不要部署在 Docker 里, 但是确实没找到具体是在哪里看到的. 但是 HeadPlane 的文档却明确提到把两个应用一起部署在 Docker 是最方便的. 个人来说, 我也是更倾向于把这类服务都容器化.
最简单的方法就是直接参考 HeadPlane 的 Integrated Mode 的文档.
services:
headplane:
image: ghcr.io/tale/headplane:0.5.10
container_name: headplane
restart: unless-stopped
ports:
- '3000:3000'
volumes:
- '/data/headplane/config/config.yaml:/etc/headplane/config.yaml'
- '/data/headscale/config/config.yaml:/etc/headscale/config.yaml'
- '/data/headplane/data:/var/lib/headplane'
- '/var/run/docker.sock:/var/run/docker.sock:ro'
headscale:
image: headscale/headscale:0.25.1
container_name: headscale
restart: unless-stopped
command: serve
ports:
- '8080:8080'
volumes:
- '/data/headscale/data:/var/lib/headscale'
- '/data/headscale/config:/etc/headscale'
对于拥有互联网连接的服务器来说问题倒是不大. 但是在大陆, GitHub Container Repository 这个仓库的镜像确实不多. 起码腾讯云在自家的镜像仓库里是只有 Docker Hub 的. 反正我当时部署的时候为了拉 HeadPlane 的镜像, 还等了挺长时间的. HeadPlane 在文档中提到说如果需要动态的 DNS 和 ACLs 配置, 需要把 docker.sock 挂在给它来实现 HeadScale 的重启.
然后是 nginx 的配置, 直接参考 HeadScale 的文档就行. 文档里还配了80端口. 我直接忽略那部分了, 只配443就够了. TailScale 默认就是要求走443的, 配80简直画蛇添足. 对于 HeadPlane, 我配了单独的域名给它. 内容就简单多了, 直接转发请求到服务上就行. 毕竟不是像 HeadScale 一样要考虑兼容客制化协议的问题.
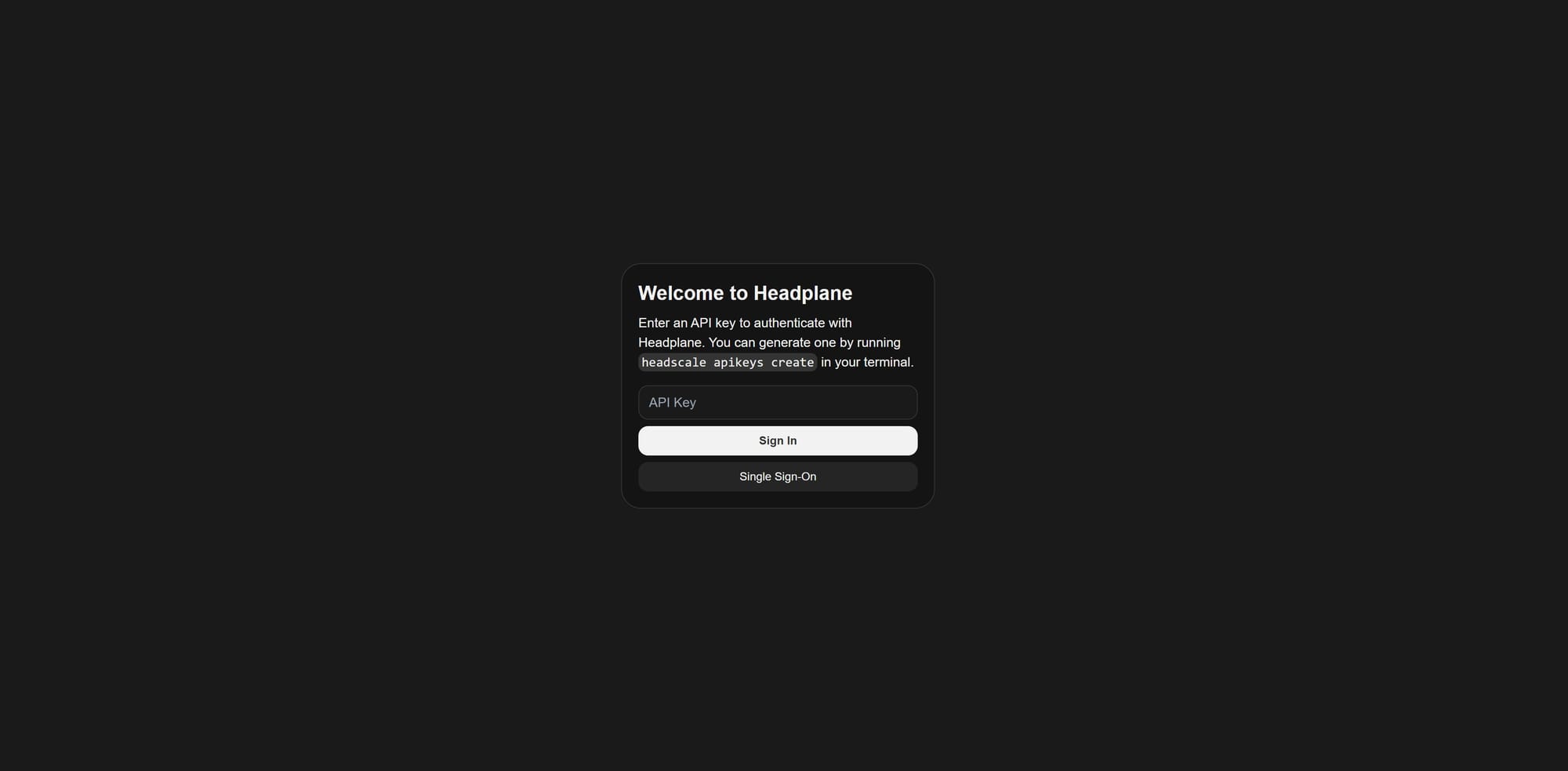
然后就想起来, 我没有 idp. HeadScale 和 HeadPlane 都支持 OIDC. 如果以最简单的配置来说, 确实直接启动就够了. 然后在登录 HeadPlane 的时候, 去部署的机子上执行一下:
sudo docker exec headscale headscale apikeys create
创建一个 APIKEY, 然后贴进去就可以了. 但是就存在一个问题, 每次登录都得贴这个 KEY, 而且这个 key 只能看到一次, 还得自己存下来.
sirius@VM-0-3-ubuntu:~$ sudo docker exec headscale headscale apikeys list
ID | Prefix | Expiration | Created
1 | xPTXBpb | 2025-07-16 02:22:15 | 2025-04-17 02:22:15
sirius@VM-0-3-ubuntu:~$
虽然不用每次都生成一次, 但是依然非常麻烦. 那就起一个 OIDC 的容器来做授权的事情喽.
一开始的方案是 Dex. 足够轻量化, 足够节省资源. 毕竟我用来部署 HeadScale 的服务器是很小的一个实例. 如果跑一个很重的类似 KeyCloak 的玩意儿, 那资源就会非常紧张了. 极简的配置如下, 只要再在 nginx 配置一个 dex 的域名和转发就可以了.
issuer: https://dex.xxx.com
storange:
type: memory
web:
http: 0.0.0.0:5556
oauth2:
passwordConnector: local
staticClients:
- id: headscale
secret: IHCigk13Q9OLzc8GCzUP
name: 'Headscale'
redirectURIs:
- 'https://headscale.xxx.com/oidc/callback'
- id: headplane
secret: oejBjO0kwgyYJnku1jrf
name: 'Headplane'
redirectURIs:
- 'https://headplane.xxx.com/admin/oidc/callback'
enablePasswordDB: true
staticPasswords:
- email: "[email protected]"
hash: "$2y$10$.begCPp1O78b7Z1xWqY1/.qcRJgywVIr7KmF9nSxwwBkVy3hOAAXi"
username: "sirius"
userID: "05ed100c-3f3d-4e21-b279-6d16b62b7921"
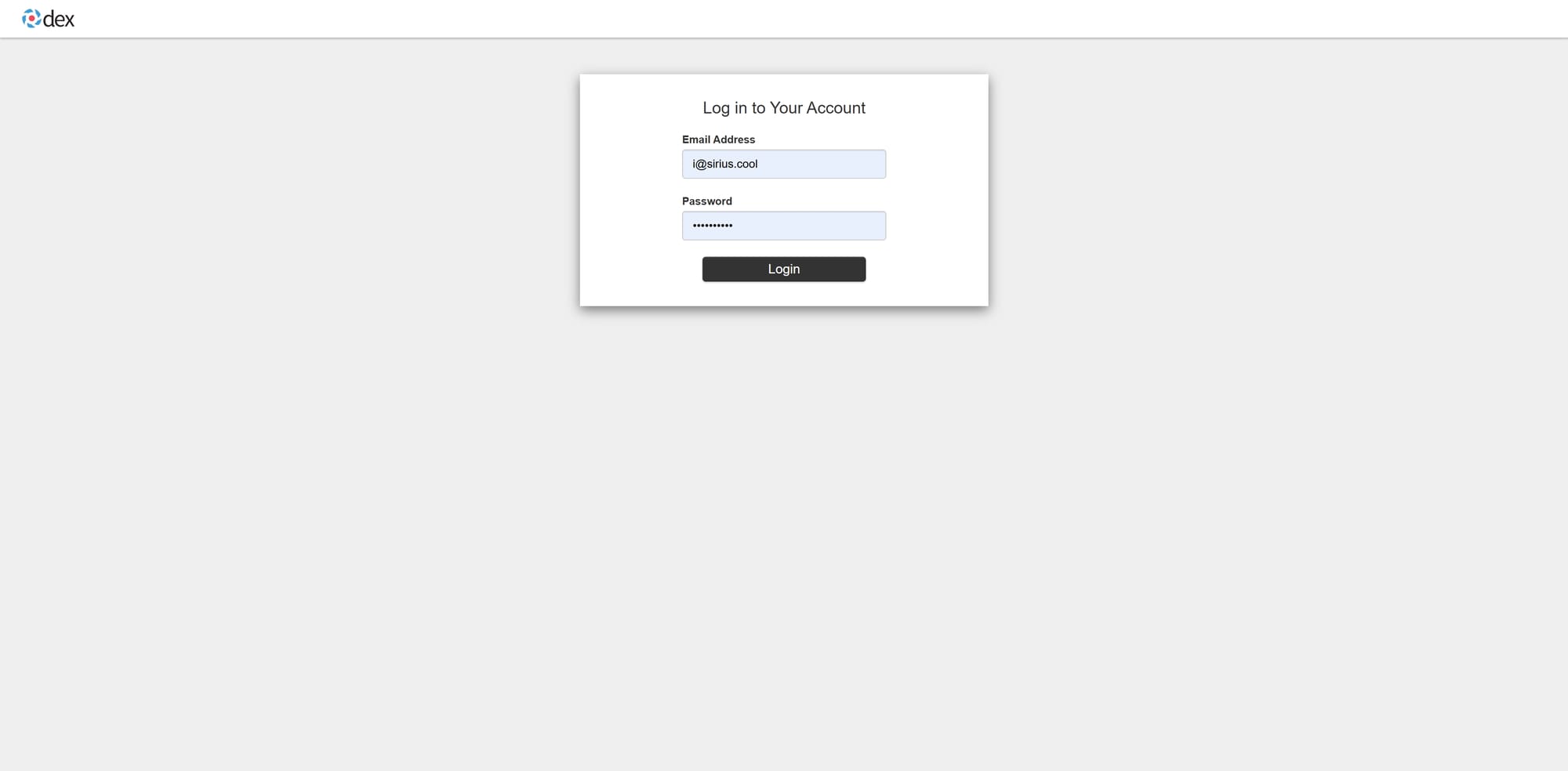
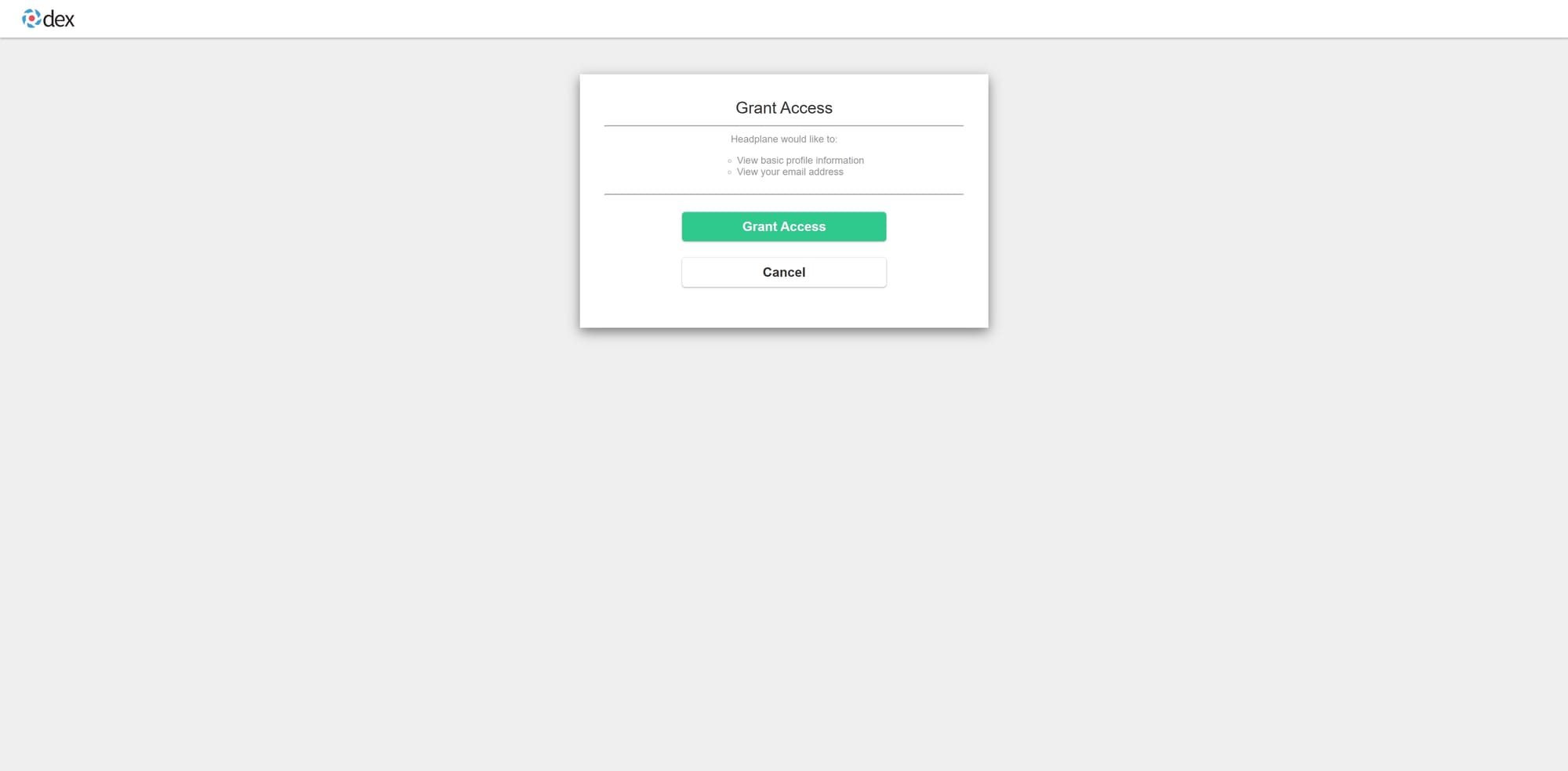
用 Dex 当然是看中它拥有在配置文件里直接定义本地用户的能力. 但是这却带来的意想不到的麻烦. Dex 的 staticPassword 并不提供标准的 OIDC claims. 这样就产生一个问题. 在 tailscale up --login-server https://headscale.xxx.com 的时候, 虽然能正常通过 Dex 授权并且注册到 HeadScale. 但是因为 claims 不全的问题, 会缺失一个字段, username. 这个问题会影响试图在 HeadPlane 创建 authkey.
sirius@VM-0-3-ubuntu:/data/dex$ sudo docker exec headscale headscale users list
ID | Name | Username | Email | Created
1 | sirius | | [email protected] | 2025-04-17 02:24:02
sirius@VM-0-3-ubuntu:/data/dex$
update: 20/04/2025 忘了提了, 在使用 OIDC 的时候, HeadPlane 和 HeadScale 之间的交互是通过 API 完成的. 所以无论如何都需要给 HeadPlane 配置访问 HeadScale 的 APIKEY. 通过 compose 来运行两个服务会产生这样的问题. 如果不运行 HeadScale, 就无法去生成这个 API KEY. 所以需要跟上面的同样的方式, 运行:
sudo docker exec headscale headscale apikey create
来生成一个 key, 并且填到 HeadPlane 的配置文件里:
oidc:
headscale_api_key: xxx
这样一来, 才能在使用 OIDC 作为用户授权的同时, 让 HeadPlane 正确的访问到 HeadScale.
对于我的使用场景来说, preauthkey 是非常重要的. 所以 Dex 这个方案只能放弃了. 既然不能用一个轻量级的 idp 的话, 那只能找个完整的 OIDC provider 了. KeyCloak 实在是太重了, 并不想用. 那么剩下的可选项就很有限了. Authentik. 进入了眼帘.
根据 Authentik 的文档说, 至少需要 2 Core, 2 GiB Memory 来部署一个实例. 但是我的服务器因为部署了 HeadScale, HeadPlane. 剩余的资源并没有这么多. 并且这台服务器也并不是只用来做 Coordination Server. 那么就好办了, 直接部署在本地, 然后利用赛博活佛的 tunnel 来访问就好了. 基本配置可以参考这里.
Authentik 的应用配置需要在系统启动了之后, 在页面上配置. 对应配置了 HeadScale 和 HeadPlane 之后流程就非常顺滑了.
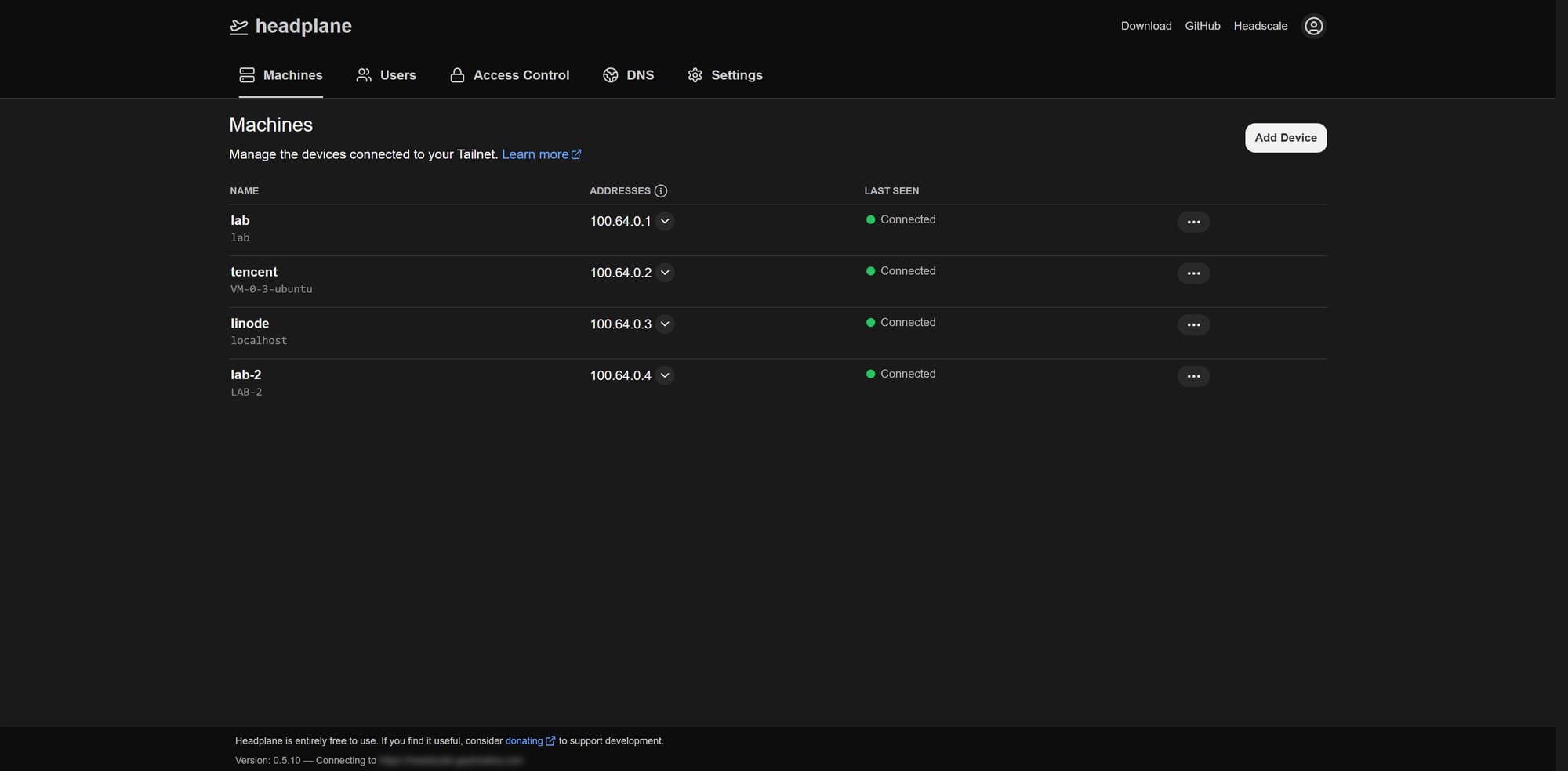
有了一个正经的 idp 之后, HeadScale 的表现总算正常了. 之后, 就剩连接自己的设备到自建的网络上了.
tailscale login --login-server https://headscale.xxx.com
然后点击授权地址就能成功把设备加入自己的网络了.
到这一步, 大部分的需求都已经满足了. 剩下的是做这整个事情的初心, 换掉 frp. 然而在这里遇到了些许挫折. TailScale 的官方 docker 镜像其实包装了一些默认的在 k8s 中的处理. 然而这些处理在云服务上的集群, 反而会造成一些麻烦.
boot: 2025/04/20 12:03:01 kubeclient: this client is not able to write tailscaled Events to the Pod in which it is running.
To help with future debugging you can make it able write Events by giving it get,create,patch permissions for Events in the Pod namespace
and setting POD_NAME, POD_UID env vars for the Pod.
boot: 2025/04/20 12:03:01 error setting up for running on Kubernetes: some Kubernetes permissions are missing, please check your RBAC configuration: multiple errors:
missing get permission on secret "tailscale"
missing update permission on secret "tailscale"
要成功运行一个 TailScale 节点其实需要两个步骤.
- 运行 TailScaled . Daemon 程序需要首先运行.
- 运行 tailscale up/login
然而对于 docker 镜像 tailscale/tailscale 来说. 单个的 entryPoint 并不够用. 于是它有了一个脱胎于 ko 的方案, containerboot. 仔细看过它的实现之后就会发现一个问题. 它会判断自己是否运行在 k8s 中. 如果是, 它会尝试一些额外的操作. 对于我来说, 我并不需要它去接入 k8s api. 只要当作一个 subnet router 就好了. 所以这个默认行为对我产生了极大的影响. 但是既然镜像里有完整的运行 tailscale client 的依赖, 那也不是没有办法. 直接覆盖掉它的启动脚本来运行自己需要的功能就好了.
tailscaled --state=mem: & sleep 5 && tailscale up --authkey=${TS_AUTHKEY} --login-server=https://headscale.xxx.com --advertise-routes=10.12.0.0/24 && tail -f /dev/null
state=mem 这个命令大概是错的, 至少我没有在官方的文档上看到这条. 然而如果我去掉这个参数, 就会导致 pod 启动报错. emmm, 懒得去探寻为什么了. 起码当前这样能够在 HeadScale 里成功注册, 并且 subnet router 确实起效了就足够了.
update: 2025/04/21. 又看了下 containerboot 的实现, 判断是否在 K8s 里运行是通过获取环境变量 KUBERNETES_SERVICE_HOST 来实现的. 因为默认会试图去和 Kubernetes API 通信. 然而在我的场景里, TailScale 只是作为一个 Relay 存在的. 不需要它去访问 Kubernetes API. 这样的话, 在 Deploy 里手动 Override 掉这个环境变量为空就好了. 也不用手动去指定命令了, 把其他的环境变量设置好:
spec:
containers:
- name: k8s-relay
image: tailscale/tailscale:stable
env:
- name: KUBERNETES_SERVICE_API
value: ""
- name: TS_AUTHKEY
value: auth_key_value
- name: TS_EXTRA_ARGS
value: --login-server=https://headscale.xxx.com
- name: TS_HOSTNAME
value: k8s-relay
- name: TS_ROUTES
value: 10.10.0.0/24,10.11.0.0/24
优雅多了.
至此, 整个使用 TailScale 替换 frp 的流程就圆满了. 再也不用通过 frp 暴露端口的方式把内网的服务暴露出去, 只需要在适当的设备上运行一个 TailScale client, 并且把自身需要对其他设备暴露的地址广播出去, 在任何一个已经加入 tailnet 的 node 上, 就可以顺畅的连接了.
当然, 除了 subnet router, Tailscale 还提供了 ACLs, 但是暂且没有时间去管理了. 毕竟能加入这个 tailnet 的全是我的设备, 短期内没有需要额外访问控制的需求. 不过过阵子闲下来了, 还是需要重新梳理目前团队对于私有网络内各种资源的访问权限, 毕竟现在有了一个完整的 idp, 而且用 TeamCity 作为 CI/CD 的方案也在推进当中. 不过对于小团队的完整方案大概不会在这篇里继续更新了. 后续还有自建 DERP, 并且让所有团队内的流量都只走直连或者自有 DERP 的实验. 这些都可以通过 HeadScale 的配置修改来实现, 就不具体写了.
以上就是这阵子折腾 TailScale 并且屡次碰壁的过程了. 祝不幸找到这篇的读者, 玩得愉快 (😀



